Часто перед нами встаёт вопрос хранения древовидных структур в базе данных. Несмотря на то, что звучит это просто, часто из-за неправильной организации хранения появляются проблемы со скоростью выборки таких данных. Есть множество приёмов как правильно организовать хранение данных в таком случае, но мы рассмотрим с вами два варианта.
Для начала давайте определим что такие древовидная структура и где её можно встретить. Самый простой вариант, который первый приходит в голову, это глубоко вложенные категории в каталоге интернет магазина или же бесконечная реферальная система.
Давайте рассмотрим данные на примере категорий каталога интернет магазина:
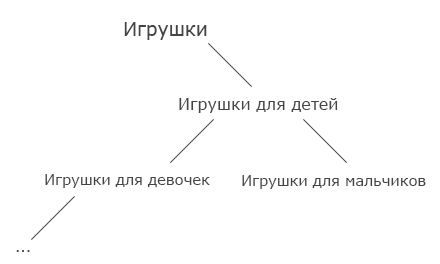
Нужно решить как мы будем хранить эти данные.
Вариант первый
| id | name | parentID (nullable) |
| 1 | Игрушки | null |
| 2 | Игрушки для детей | 1 |
| 3 | Игрушки для девочек | 2 |
| 4 | Игрушки для мальчиков | 2 |
Схема таблицы для категорий каталога;
Пока всё выглядит хорошо. Каждый товар имеет categoryID, которая связана с нашей таблицей категорий. Проблемы начинаются тогда, когда нам нужно определить все дочерние или все родительские категории. Зачем? К примеру, когда пользователь выбрал категорию игрушек нам нужно отобразить все товары, которые привязаны к этой категории и к дочерним категориям. В таком случае нам придётся делать n запросов, где n кол-во элементов в нашей структуре. Уже не всё так хорошо, не так ли?
Оптимизация
Чтобы оптимизировать работу с поиском предков и дочерних записей мы прибегнем к кешированию структуры. В таком случае алгоритм будет следующим, рассмотрим на примере получения всех дочерних категорий для категории Игрушки:
{parentID} – id категории Игрушки
- Ищем запись в кеше по ключу anyKey_{parentID}. Если данные найдены, то переходим к пункту 3. Иначе находим все дочерние элементы категории, выбираем только их id. На выходе мы получим коллекцию, которая будем содержать id дочерних элементов.
- Сохраняем коллекцию id в кеше по ключу anyKey_{parentID}, где parentID – это id категории Игрушки.
- Делаем запрос в базу данных на выборку категорий по id из нашей коллекции.
Таким образом получается, что трудоёмкая операция поиска дочерних элементов для конкретной категории выполняется единожды. В остальных случаях данные берутся из кеша.
Резюме
Такой подход лучше всего использовать только в том случае, когда не планируется глубокая вложенность. Ведь работать без головной боли можно в случае, если у данных единичная вложенность. Если всё же вложенность большая, а изменить способ хранения нельзя, то вам придётся заняться кешированием данных.
Плюсы:
+ Данные о вложенности находятся в этой же таблице;
+ Можно быстро реализовать: добавив поле parentID и всё;
+ Быстрая вставка данных;
Минусы:
– Чем больше вложенность, тем больше проблем;
– Выбрать все дочерние или все родительские записи одним запросом невозможно;
– Сложно считать глубину вложенности;
Вариант второй
Суть второго варианта заключается в создание вспомогательной таблицы, которая будет хранить данные о положение в дереве.
| id | name |
| 1 | Игрушки |
| 2 | Игрушки для детей |
| 3 | Игрушки для девочек |
| 4 | Игрушки для мальчиков |
Таблица категорий. Мы избавились от parentID.
| id | parentID | childID | level |
| 1 | 1 | 1 | 0 |
| 2 | 1 | 2 | 1 |
| 3 | 1 | 3 | 2 |
| 4 | 1 | 3 | 2 |
| 5 | 2 | 3 | 1 |
| 6 | 2 | 4 | 1 |
Вспомогательная таблица, которая хранит данные о местоположение в дереве
Во вспомогательной таблице хранятся отношения между записями: parentID-childID (предок-дочерний элемент), level (удалённость записей друг от друга в дереве). Если вы заметили, то у записи ID 1 я установил level 0, я сделал это для того, что бы с лёгкостью можно было идентифицировать корневые записи (записи, у которых нет предков).
На картинке наглядно показано как высчитывается удалённость на примере категории Игрушки:
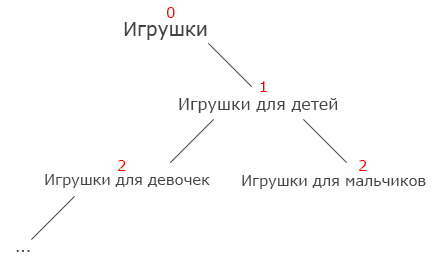
В этом варианте нам заранее нужно позаботиться об алгоритме вставке данных. Алгоритм вставки корневой записи простой, поэтому рассмотрим алгоритм вставки дочерней записи:
- Находим запись под которую (O) необходимо вставить новую запись (N);
- Находим все записи, у которых childID равен O.id и level > 0;
- Копируем записи найденные для записи O, заменяя childID на N.id, а для каждой записи увеличиваем level на 1;
- Создаём запись, у которой childID = N.id, parentID = O.id, level = 1;
- Сохраняем. Теперь у нас есть данные о взаимосвязи со всеми записями-предками.
Резюме
Этот подход очень хорошо работает с данными, у которых очень глубокая вложенность. Всего лишь одни запросом можно найти: всех предков, всех дочек, все корневые узлы, все крайние узлы. Данный алгоритм хорошо работает в том случае, если новые записи вставляются редко. Если новые данные появляются часто, то придётся пути оптимизации.
Плюсы
+ Быстрая работа с глубокой вложенностью;
+ Все операции связанные с деревом компонентов выполняются в один запрос
Минусы
– Вставка новой записи затратна по ресурсам;
– Требуется определённое время на развёртывание;